Uncovering People's Dirty Little Secrets on Venmo with Python Web Scraper
Of course, Venmo is perfect for splitting up the bills from that crazy night out with your friends. Yet, it is easy to forget about the pitfall of the convenience at your fingertip—your privacy compromised.
In fact, all payments you make through Venmo are publicly accessible unless you make them specifically private. These public data can offer some interesting insights, such as what people (supposedly) buy and how much they spend. While I was searching for an adequate topic for my final project for an NYU class called Python for App this spring, a more interesting, perhaps mischievous, question came to my mind: “What kind of bad things do people buy through Venmo?”
With some research, I was able to find relevant data on a website called Vicemo.com. Built by two developers, Mike Lacher and Chris Baker, Vicemo.com uses Venmo API and JavaScript to collect real-time, public Venmo transactions involving drugs, booze, and sex.
Voila!

Using web scraping tool will allow us to quickly collect the data without intensive coding involving the Venmo API.
Introduction
For this project, I use Python, a powerful tool for web scraping. However, after visiting Vicemo.com, I quickly realized its content is delievered completely through JavaScript. It can be challening to get the data from the website that depends on JavaScript to dynamically render its content. Using Python modules such as Requests and BeautifulSoup may not be so fruitful as the content on such websites loads only when the user activity on the browser calls the corresponding JavaScript. While struggling to solve this problem, I found a potential solution from a blog post by Todd Hayton, a freelance software developer. An effective way to get around this problem is to use Selenium, a tool for automating browsers, and PhantomJS, a non-GUI (or headless) browser.
Implementation
First, we need to install PhantomJS and Selenium bindings for Python. I am quoting the code snippet from Hayton’s blog post.
$ mkdir scraper && cd scraper
$ brew install phantomjs
$ virtualenv venv
$ source venv/bin/activate
$ pip install seleniumOr, you can download PhantomJS and Selenium manually and place them in your virtual environment library. The below are the links:
- PhantomJS: http://phantomjs.org/download.html
- Selenium: http://www.seleniumhq.org/download/
Now, let’s see how this is done.
There are three tasks that need to be done in the following order:
- Scrape web elements
- Parse HTML elements
- Cleanse data
We create three classes to do these tasks–LetMeScrapeThat, LetMeParseThat, and LetMeAnalyzeThat. An additional class that instanciates these three classes is VicemoScraper. The below is the code snippet that showcases how PhantomJS and Selenium are used.
import re
from selenium import webdriver
from bs4 import BeautifulSoup
from time import sleep
class LetMeScrapeThat(object):
def __init__(self):
print("Accessing data.")
self.phantom_webpage = webdriver.PhantomJS()
self.phantom_webpage.set_window_size(1120, 550)
def scrape_vicemo(self, link, howmany = 100):
self.phantom_webpage.get(link)
print("Visiting the data source: {}".format(link))
print("Please, wait.")
sleep(2) # We make the scraper wait until the website loads completely
for i in range( howmany // 100 - 1 ):
self.phantom_webpage.execute_script("window.scrollTo(0, 10000);")
# Each scroll yields 100 transactions on Venmo
sleep(2)
# The web driver has to sleep so that all data can load
webele = self.phantom_webpage.find_elements_by_class_name("transaction")[:howmany + 1]
# enter list comprehension to extract the HTML codes from each web element
self.transactions = [ele.get_attribute("innerHTML") for ele in webele]
self.phantom_webpage.quit()First, the class, LetMeScrapeThat, instantiates a PhantomJS headless browser by calling webdriver.PhantomJS(). We then access the target website via the method self.phantom_webpage.get(link). Note how the method sleep() from time is called to let JavaScript render the desired data completely. In addition, the for loop in the method scrape_vicemo() allows us to scroll down in our PhantomJS browser to access more data, which are rendered dynamically as the user scrolls down the page. Finally, we extract the HTML codes from the web elements and store them in the list variable self.transactions.
Let’s now take a look at LetMeParseThat, which parses HTML codes to extract the data. Here is the example how the data might look like after being rendered by JavaScript.
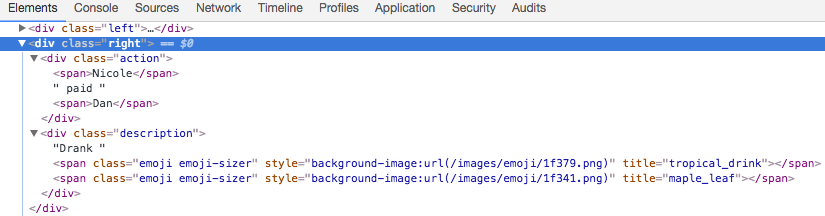
Note that the description of the transaction is within <div> tag with class="description". Also, note how the emojis are represented by the attribute title=emoji-name of the <span> tags.
Take a look at the code snippet for LetMeParseThat() class below.
class LetMeParseThat(object):
def __init__(self,list_of_html):
print("Parsing data.")
self.soup_list = [BeautifulSoup(html, "html.parser") for html in list_of_html]
self.desc_tags_compiler =[soup_ele.find_all('div',attrs={'class':'description'}) for soup_ele in self.soup_list]
def extract_string_data(self):
# extracts strings from the <div> tags with class="description"
self.string_compiler = [soup_ele.find('div', attrs={'class':'description'}).string
for soup_ele in self.soup_list
if soup_ele.find('div', attrs={'class':'description'}).string]
def extract_emoji_data(self):
# extracts emojis from the <span> tags with class="emoji emoji-sizer"
self.emoji_compiler = []
for soup_ele in self.soup_list:
for span in soup_ele.find_all('span', attrs={'class':['emoji','emoji-sizer']}):
self.emoji_compiler.append(span['title'])As observed, the description of the transactions comes in both strings and emojis, so we use extract_string_data() and extract_emoji_data() methods to extract the strings and emojis from HTML accordingly.
Moreover, these data need to be cleansed before we can use them. The class LetMeAnalyzeThat does this job.
class LetMeAnalyzeThat(object):
common_english_words = ['the', 'be', 'to', 'of', 'and', 'a', 'in', 'that', 'have', 'I', 'it', 'for', 'not', 'on', 'with', 'he', 'as', 'you', 'do', 'at', 'this', 'but', 'his', 'by', 'from', 'they', 'we', 'say', 'her', 'she', 'or', 'an', 'will', 'my', 'one', 'all', 'would', 'there', 'their', 'what', 'so', 'up', 'out', 'if', 'about', 'who', 'get', 'which', 'go', 'me', 'when', 'make', 'can', 'like', 'time', 'no', 'just', 'him', 'know', 'take', 'people', 'into', 'year', 'your', 'good', 'some', 'could','them', 'see', 'other', 'than', 'then', 'now', 'look', 'only', 'come', 'its', 'over', 'think', 'also', 'back', 'after', 'use', 'two', 'how', 'our', 'work', 'first', 'well', 'way', 'even', 'new', 'want', 'because', 'any', 'these', 'give', 'day', 'most', 'us', '']
def __init__(self):
print("Analyzing data.")
def analyze_string_data(self, string_data):
vice_compiler = []
for ele in string_data:
for word in ele.split():
# cleanse the word using Regular expression and string methods
regex = re.compile('[^a-zA-Z]')
cleansed_word = regex.sub('',word.lower().rstrip())
vice_compiler.append(cleansed_word)
# creates a dictionary of unique words with zero initial count
# drop the word in the dictionary if it is just a useless common English word
self.vice_str_dict = {key : 0 for key in set(vice_compiler) if key not in self.common_english_words}
for ele in vice_compiler:
if ele in self.vice_str_dict:
self.vice_str_dict[ele] += 1
return self.vice_str_dict
def analyze_emoji_data(self, emoji_data):
# creates a dictionary of unique emojis with zero initial count
self.vice_emoji_dict = {key : 0 for key in set(emoji_data)}
for ele in emoji_data:
if ele in self.vice_emoji_dict:
self.vice_emoji_dict[ele] += 1
return self.vice_emoji_dictNote most commonly used English words are hard coded to help the program filter out trivial words. Remember, we are only interested in what Venmo users are paying for. Using Regex, we get rid of special characters and whitespaces from words. The clenased words are then added to a compiler. A similar process is carried out to extract emoji data. The resulting outputs are dictionaries containing the objects or activities Venmo users paid for and how many times it appears in the collected data. Finally, we have all the tools to obtain the data.
Conclusion
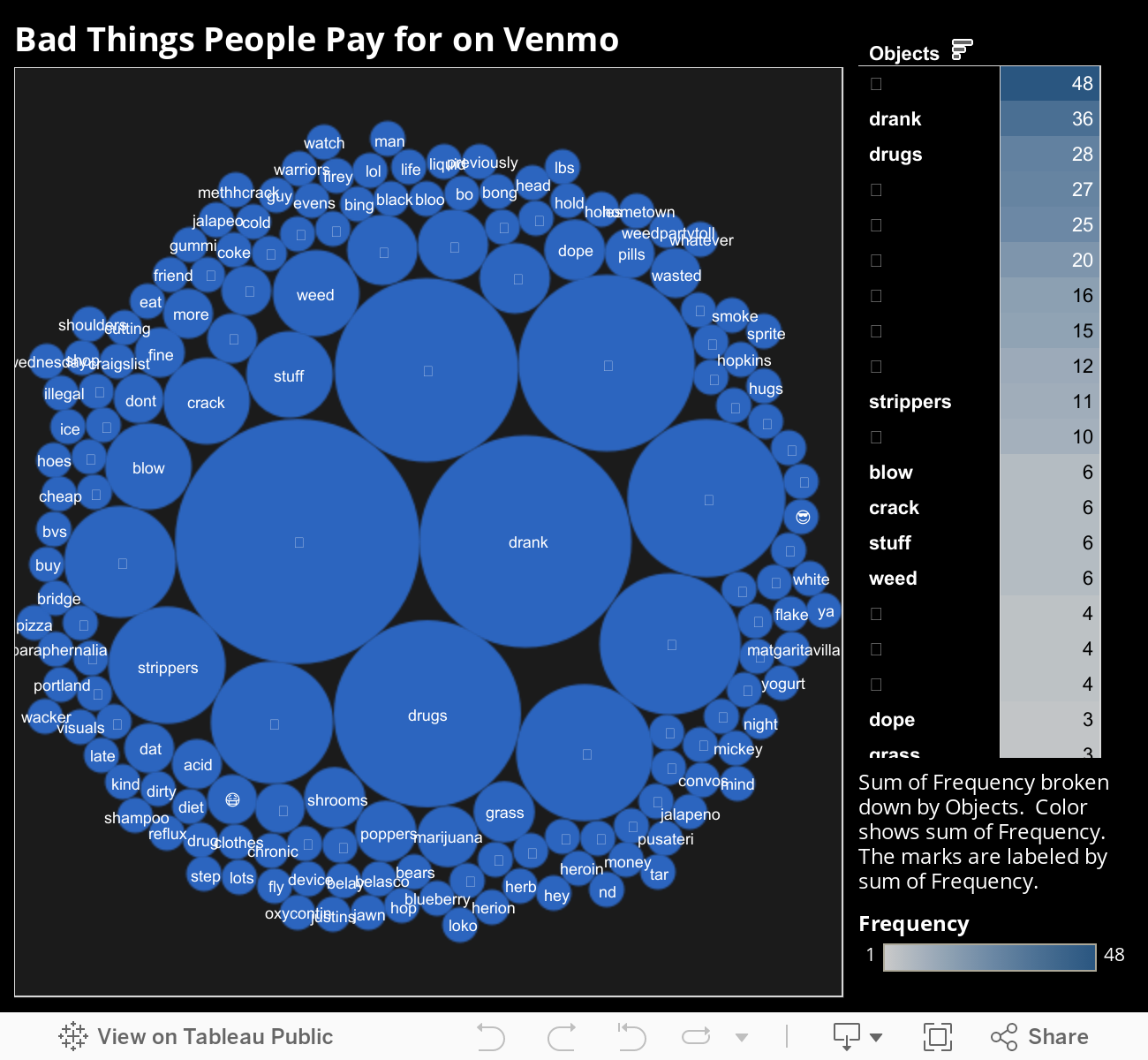
The working version of the codes from this project is available on Github. Here is the link. There are many different ways to use this data. The below is an example of visualization that I created using Tableau Public with the data that were obtained on July 27th.